
Productivity wen?!?
Probly soon

We intuitively understand that the value of an AI assistant is a function of both its speed and its accuracy. But the relationship between these factors and actual productivity is complex.
If an AI completes a task in 10 minutes that takes me an hour, but I have to spend 55 minutes fixing its mistakes, I’ve lost time. The assistance was actively harmful on this task. Worse still, it can also have second order costs. I’ve often found that by fixing rather than generating cognitive work from scratch, I think less deeply about the task and achieve a weaker level of domain understanding.
The first order cost dynamic is illustrated nicely in GDPval, a new benchmark from OpenAI. GDPval measures model performance on economically valuable, “predominantly digital” tasks across 9 major US sectors (Finance, Healthcare, Real Estate, etc.) that each contribute over 5% to US GDP.
The tasks are substantial, averaging approximately 7 hours for an experienced human professional to complete (roughly 360 USD at median wage estimates) and approx. 2 hours for a professional to review. By modelling the cost of human review, GDPval illustrates something interesting:
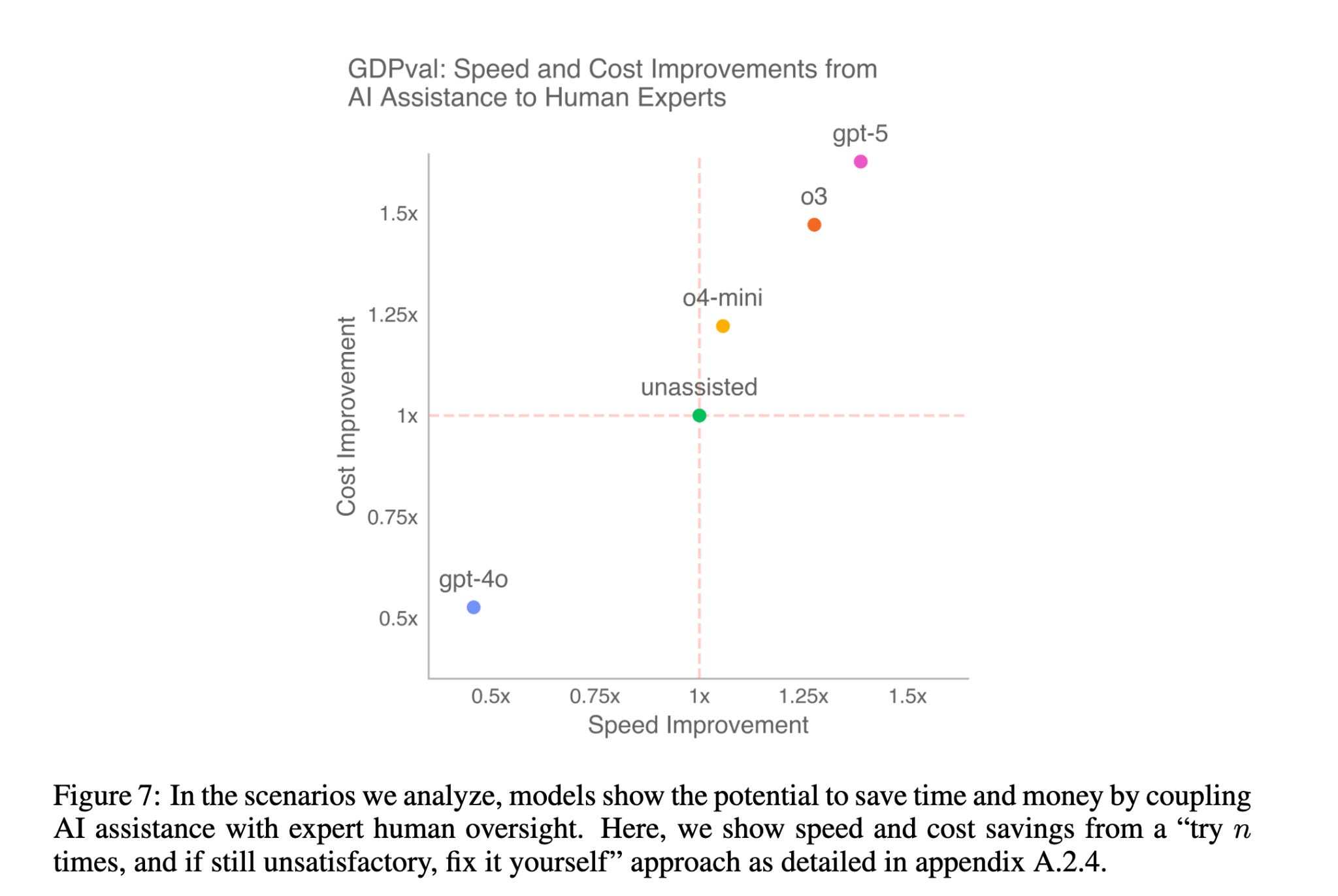
Look at gpt-4o. By historical standards, it is a very capable model. Yet, on this distribution of complex tasks, it is a net negative. The cognitive load and time cost of reviewing and correcting its output outweigh the initial speed advantage. This finding rhymes with the observation in the 2025 METR coding study that showed that AI assistance on average made experienced coders 19% slower.
One important caveat is in order here: the GDPval cost and speed improvements are estimated using a simple task completion model based on winrate and human review time, rather than measured directly (see the paper for details), so these numbers should be treated with a grain of salt. Second order costs are not accounted for.
Only the frontier models (in this plot gpt-5, o3, o4-mini) cross the threshold where AI assistance becomes meaningfully economically viable for this type of knowledge work. They are good enough that the review/fix process no longer dominates.
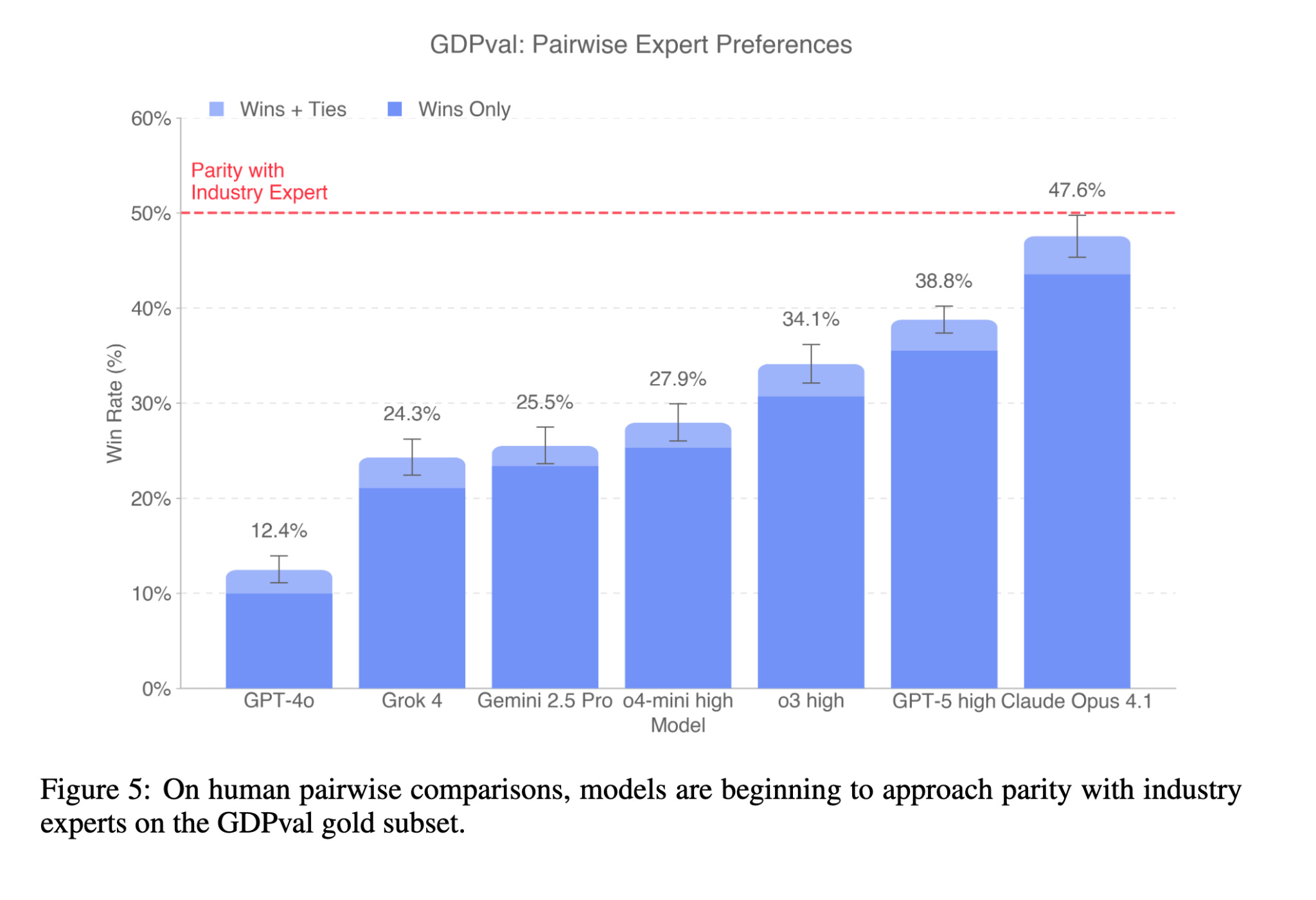
Of course, individuals who work regularly with AI models develop intuition for where they help and where they hurt. We don’t use these models everywhere, only on tasks with high leverage. And the capability progress at the frontier is rapid. When comparing models head-to-head against human experts, the gap is nearly closed, with Claude Opus 4.1 approaching parity (47.6% wins or ties).
Focusing solely on frontier models from OpenAI, we also see that progress over time has been substantial:
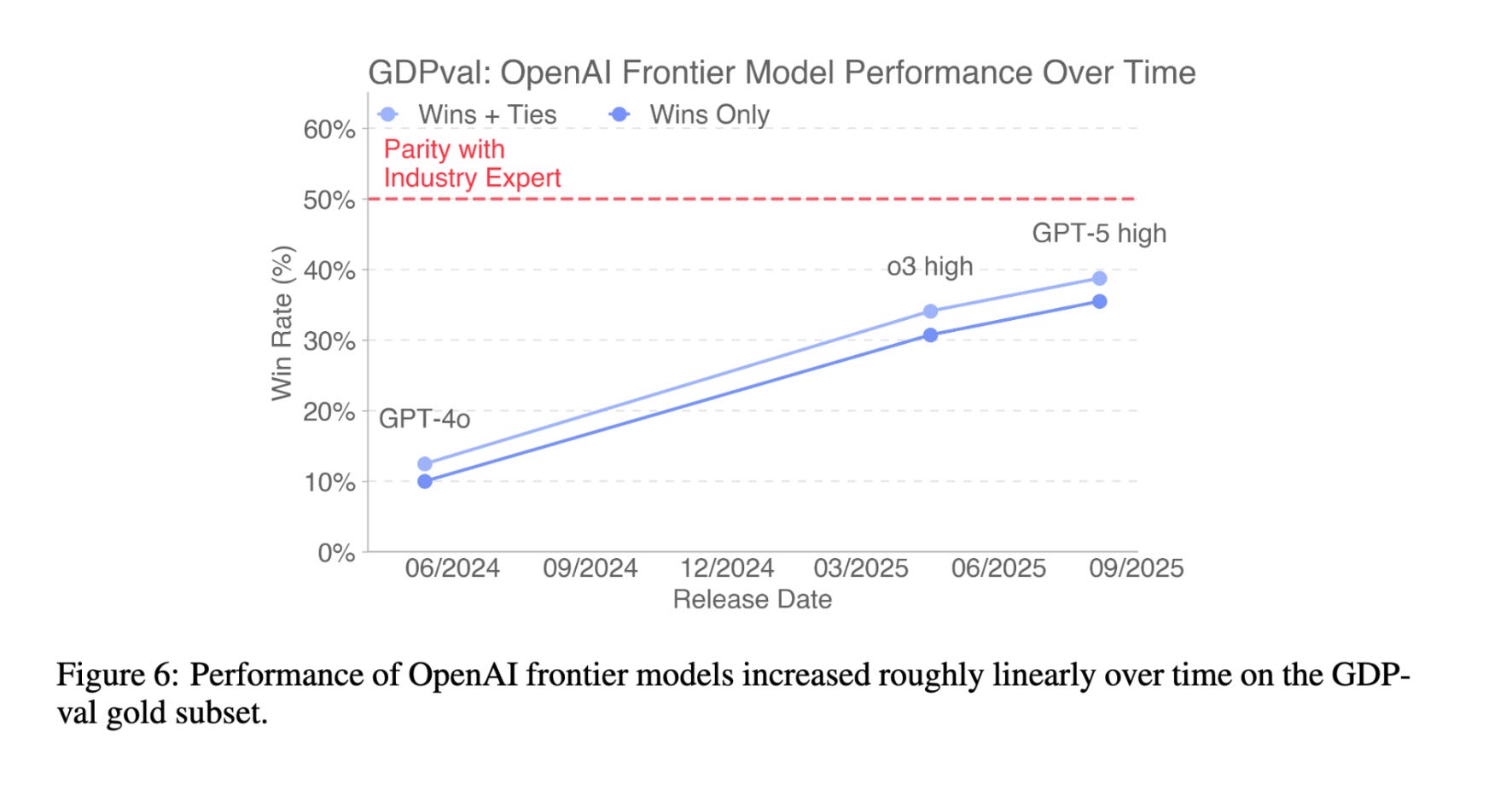
I believe the Gods of Straight Lines on Graphs predict that this will continue.
So, productivity wen?!?
Robert Solow once quipped, “You can see the computer age everywhere but in the productivity statistics.“ Will the same be true of AI?
Historically, it has taken a long time for the true economic impact of a new technology to show up in the data. Macroeconomic statistics are often lagging indicators. Ambitious, forward-looking benchmarks like GDPval are not perfect. As the authors highlight, GDPval consists of precisely specified, self-contained, computer-oriented knowledge work that does not span the full economy. Nevertheless, such benchmarks are among the best tools we have for creating leading indicators. If progress continues at current rates, it is my view that we may not have to wait too long for productivity gains to manifest. Probly soon.
Other fun findings in the paper: (1) Claude 4.1 Opus is actually weaker than several other frontier models on text-only tasks, but it absolutely dominates on tasks involving files (particularly PowerPoints and PDFs); (2) The authors run a nice ablation studying the impact of “undercontextualized tasks” (tasks for which the instructions are more ambiguous) - interestingly, this made relatively little difference to gpt-5 performance. This reflects my experience, which is that modern models are pretty good at inferring intent from poorly written instructions.
Other news
Legendary Software Engineer Julian Schrittwieser weighs in on AI progress: “Failing to understand the exponential, again” By extrapolation, he suggests that models will be able to autonomously work for full days (8 working hours) by mid-2026.
Moving to a different kind of complex benchmark, the UK shows that it is still SotA on the ‘State Banquet’ eval. Here’s the King’s place setting.
DeepSeek V3.2-Exp reports efficiency gains with Sparse Attention. Top-K is all you need.
Claude Sonnet 4.5 is out. It’s good at financial analysis. I eagerly await Zvi Mowshowitz’s review.